데이터가 많다면 최적화라도 좋아해 주실 수 있나요?
여러개의 기기들 상태 데이터를 빠르게 보여주고 싶어요!
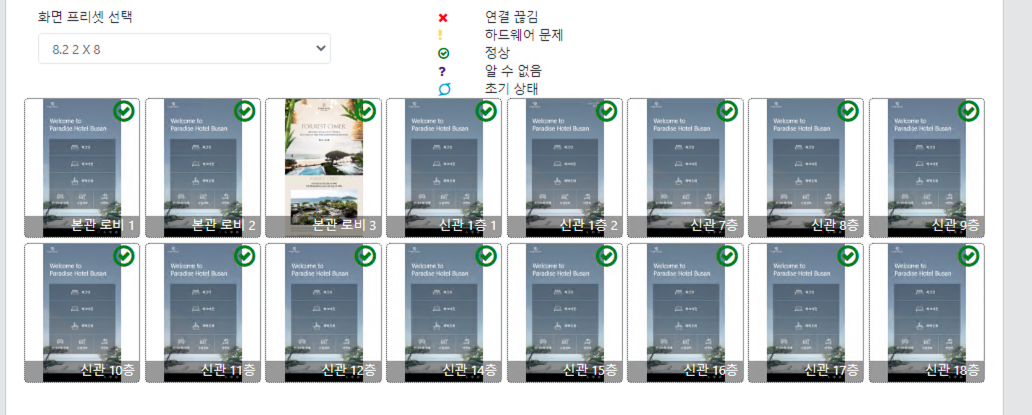
위의 사진은 관리자 페이지에서 건물 내 설치된 키오스크들의 현재 화면 상태를 모니터링 하는 화면입니다. 매 10초 마다 각각의 기기들로 부터 상태 데이터를 받아 들이며, 관리자 페이지에서는 매 10초 마다 API 서버에 요청을 걸어 기기들의 최신 상태를 받아 옵니다.
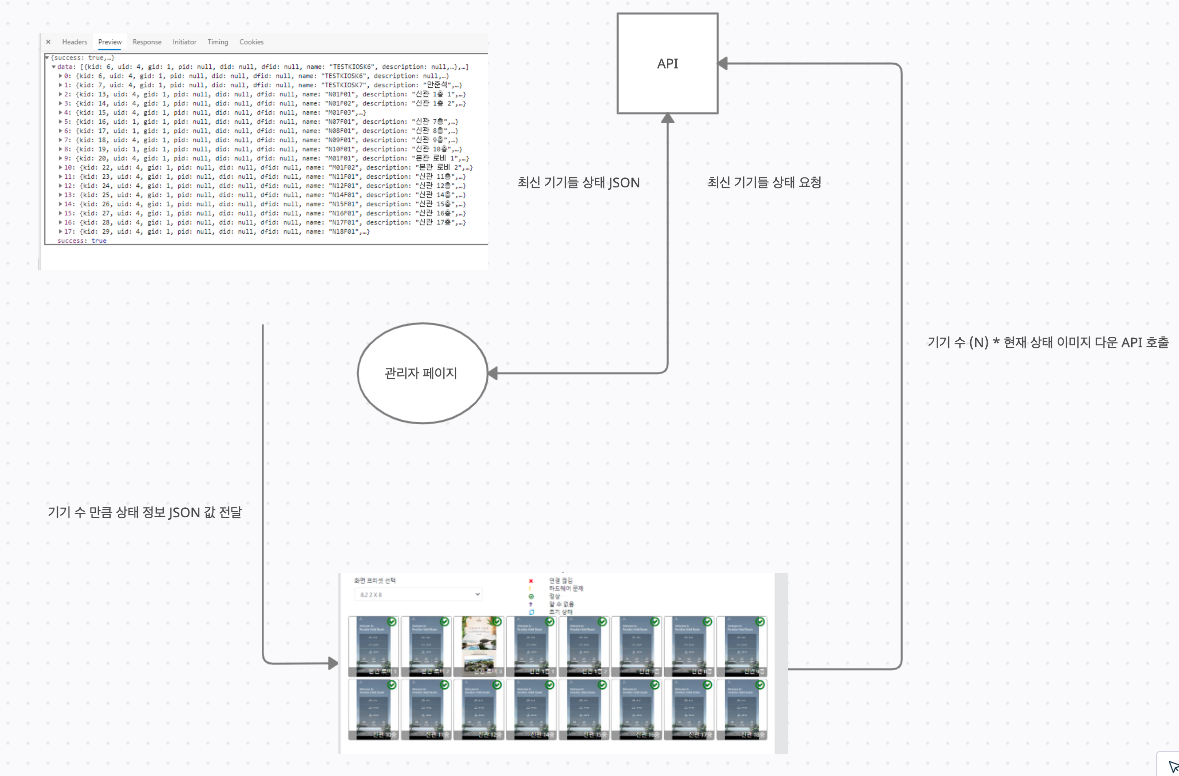
위와 같이 플로우가 진행되어지는데 문제가 되어지는 부분은 각 기기들의 수 만큼 이미지를 로드 하는 부분에서 발생합니다.

저거 가지고 왜? 어떤 문제가 발생되는데?
너무 큰 사이즈의 이미지를 다운로드 함으로 인해 발생되는 트래픽 처리량 증가
HTTP 1.1 사용으로 인한 같은 도메인 내 동시 다운로드 제한
이미 DB에 등록된 상태 값 데이터가 많아짐으로 인해 발생되는 쿼리 성능 저하
이전에 불러왔었던 이미지를 또 요청하면 같은 동작을 반복하게 되어 백엔드의 부담 증가
에이 저 문제들 가지고 많이 나빠 지겠어?

라고 생각했었지만 실제로 처리를 해보니 현재 기기 상태를 가져오는데만 약 5초가 소요되었고 웹 서비스 특성상 1초를 기다리지 못 하는 클라이언트에겐 좋지 못한 성능을 보여주고 있었습니다.
3가지 문제들을 해결해 내간 과정에 대한 내용을 하단에 기술해볼까 합니다.
1. 너무 큰 사이즈의 이미지를 다운로드 함으로 인해 발생되는 트래픽 처리량 증가
각 기기들의 해상도는 FHD 세로형 입니다. 즉, 매 10초 마다 FHD 해상도의 스크린 샷을 찍은 후 서버에 전송을 하게 됩니다.
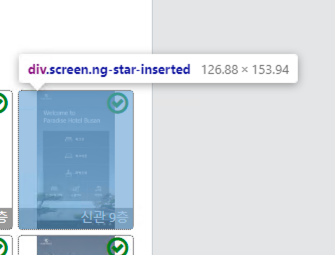
하지만, 아까 보았던 것과 같이 각 기기별 화면 상태를 보여주는 영역의 크기를 살펴보면 약 126 X 153 의 크기로 사진을 출력하고 있습니다.
FHD 급 해상도의 이미지가 필요 없으며, 위의 경우 16대의 화면을 렌더링 하고 있으니 FHD X 16 사진을 한 화면에서 렌더링 할 필요가 없습니다.
그리하여 서버사이드 이미지 압축 방식을 구현해야 했습니다.
return sharp(fileSavedPath)
.png({compressionLevel: 9, adaptiveFiltering: true, force: true})
.resize(270, 480)
.toFile(destPath);
}
sharp 을 이용해 최대한 압축을 하며 해상도를 270 X 480 형태로 줄임으로서 50KB 대의 이미지를 생성하며, 다운로드 할 수 있게끔 구현을 하였습니다.
하지만 이로인해 생기는 문제가 있었는데 동시에 매 10초 마다 16대의 기기들이 사진을 보낼때마다 압축이 되어지는 바람에 CPU 사용률이 높아지게 되었습니다.
다행이 이 부분은 쉽게 해결되었는데 바로 각 기기들에서 보내기 전에 기기 단에서 압축을 한 이미지를 업로드 하게끔 클라이언트 개발자와 협의를 하였습니다. 각 기기들은 CPU 자원 사용률이 평균 50%도 안되는 여유로운 상태였기 때문에 서버에 할 일을 몰아주지 않고, 분산시켜서 작업이 되어지게끔 변경을 하였고 덕분에 서버의 자원 사용량은 적어지면서 이미지 전송 트래픽은 줄일 수 있었습니다.

물론 제가 관리할 코드가 적어 졌다는게 제일 기분이 좋았지만 말이죠
2. HTTP 1.1 사용으로 인한 같은 도메인 내 동시 다운로드 제한
안타깝게도 저희 서비스는 내부적으로 사용되어지는 관리자 페이지이므로 도메인과 HTTPS 가 사용되어지지 않았습니다. 그렇다면 HTTP1.1 을 사용해야 한다는 이야기가 되는데 여기서 문제가 생깁니다.
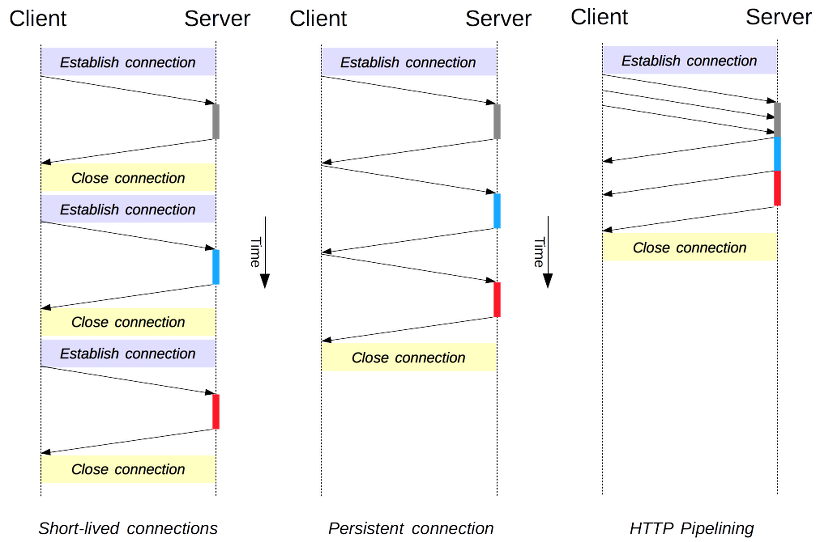
HTTP 1.1 의 가장 큰 특징은 HTTP 1.0 당시 매 요청이 끝나면 새로운 요청을 체결하였고 한 요청이 끝날 때 까지 기다렸기 때문에 지속적 연결과 pipeline 으로 여러개의 요청을 보낼 수 있게끔 변경되었습니다.
하지만 이 부분도 문제점이 브라우저 별로 HTTP1.1 기준 보낼 수 있는 요청의 수 가 제한되어 있다는 점입니다.
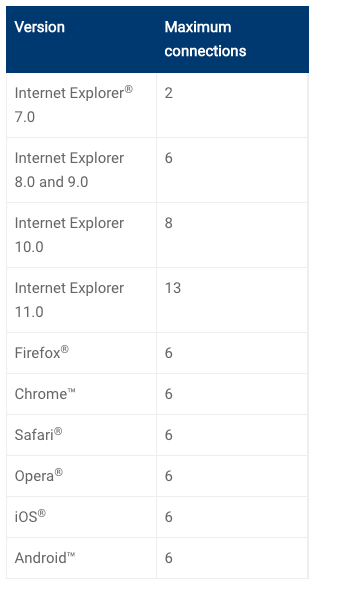
대략 이런 식이죠. 그럼 위에 보았던 기기별 상태 화면에선 16대의 기기를 보아야 하지만 경우에 따라선 동시에 화면 이미지가 다운로드 되어지지 않고, 6 개 씩 나누어서 갱신되어지게 됩니다. 물론 HTTP2.0 의 경우엔 한 도메인에 여러개 요청이 제한되어 있지는 않아 바로 해결될 수 있는 문제이죠.

stack ref 하지만 경우에 따라선 제한이 있을 순 있다는 것 같지만
내부망이었기 때문에 도메인 사기엔 좀 그랬기에 이미지를 비동기로 다운받아온 다음 한번에 갱신하는 로직을 구현하게 됩니다. 한땀 한땀
getMonitScreens(monitoringList: MonitoringModel[]) {
const prom: any[] = [];
monitoringList.forEach(monit => {
if (monit.deviceStatusJson && monit.deviceStatusJson.length > 0 && monit.deviceStatusJson[0].rfid) {
const latestMonit = monit.deviceStatusJson[0];
prom.push(this.downMonitScreen(
monit.kid,
`<API_IMAGE_DOWNLOAD_URL>`,
latestMonit.contentType
));
} else {
monit.blobUrl = '<DEFAULT_IMG_URL>';
}
});
return this.allSettled(prom);
}
각 기기들 상태를 배열로 받아 들이고 현재 상태 정보가 담긴 json object 에서 이미지 정보를 참조하여 Promise 로 이미지 다운 로직을 호출 하였고 각 Promise 객체는
prom.push(this.downMonitScreen(
monit.kid,
`<API_IMAGE_DOWNLOAD_URL>`,
latestMonit.contentType
));
prom으로 선언하였던 배열에 push 하였습니다.
이후 모든 Promise 객체가 완료되었을 시 콜백을 반환 받기 위해 allSettled 로 호출한 결과를 반환하도록 하였습니다.
이렇게 되어지면 모든 이미지가 비동기로 다운이 받아지게 되며 모든 이미지가 다 다운 된 다음 작업을 진행 할 수 있기 때문에 웹 페이지 화면에도 기기 화면들을 한번에 갱신 할 수 있게 되었습니다.
3. 이미 DB에 등록된 상태 값 데이터가 많아짐으로 인해 발생되는 쿼리 성능 저하
위의 최적화가 이루어지더라도 문제가 되는 부분이 있었는데 앞에 말한 것과 같이 기기의 상태 정보를 매 10초 마다 등록하였으므로 DB에 데이터가 많아져 쿼리 처리 속도가 느려졌습니다.
마지막으로 확인했던 쿼리의 결과를 반환하는데 걸린 시간이

0.6초

이미지 26.4KB 용량을 다운받는데 총 걸린 시간이 1초 인데 0.6초를 프로시저 수행에 사용되어지고 있으니 당연히 DB 서버 자체에도 무리가 갈 뿐더러
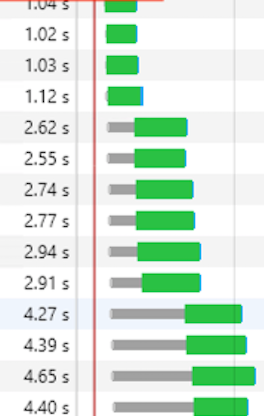
누적되면 누적되어질 수록 로드 하는데 시간이 오래 걸리게 되었습니다.
그럼 쿼리 최적화를 하면 되는 것 아닌가? 싶지만 안타깝게도 좋은 최적화 방법에 대해 알지 못 하여 진행하진 못 하였고 대신 눈에 들어오는 서비스가 있었는데 바로바로 Redis 서버!

그렇다고 한다. 사진을 가져오기 위한 쿼리가 느리다는게 문제이므로 쿼리 결과를 미리 캐싱하여 같은 이미지를 요청 할 시 캐시된 결과를 바탕으로 조회하여 반환하도록 구현을 하도록 하였다.
플로우는 다음과 같다
- 기기 상태 등록시 업로드 되는 사진의 DB 정보를 레디스에 저장
- 이미지 다운로드 요청
- 이미지 정보 조회 방식 중
Redis에 먼저 등록여부 확인 - 등록 되어 있을 시
Redis에 저장된 정보 사용
하지만 이 과정에선 새로운 이미지를 등록 할 경우에만 레디스 참조가 되었으므로 개선을 하면
- 기기 상태 등록시 업로드 되는 사진의 DB 정보를 레디스에 저장
- 이미지 다운로드 요청
- 이미지 정보 조회 방식 중
Redis에 먼저 등록여부 확인 - 등록 되어 있을 시
Redis에 저장된 정보 사용 4-1. 없을 시 DB 조회 후 결과를Redis에 등록
으로 변경 하였다.
여기서도 문제가 되어지는데 만약 이미지가 삭제 되었다면? Redis 에도 삭제가 되어야 한다. RAM 메모리 사용하는 특성상 반환하지 않을 시 메모리 사용량이 증가만 하게되어 언젠간 터지게 되기 때문이다.
이로서 나온 결과는?
| 전 | 후 |
|---|---|
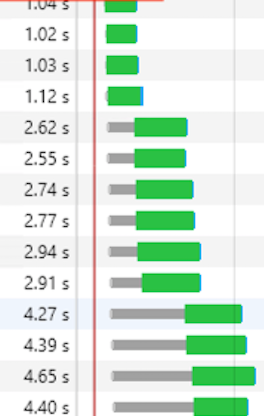 |
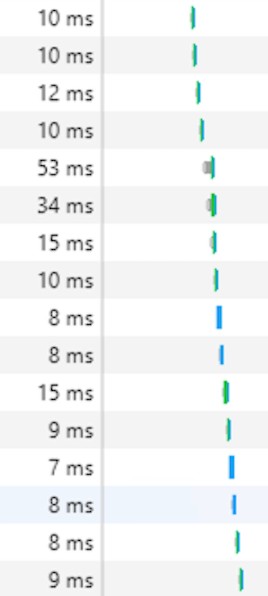 |

와! 겁내 빠르다!
4. 이전에 불러왔었던 이미지를 또 요청하면 같은 동작을 반복하게 되어 백엔드의 부담 증가
위의 3번 까지는 실시간 변화하는 이미지를 출력하기 위한 최적화의 방식이었다면, 지금은 한번 올려놓은 이미지를 매번 요청때 마다 불러오는 경우이다.
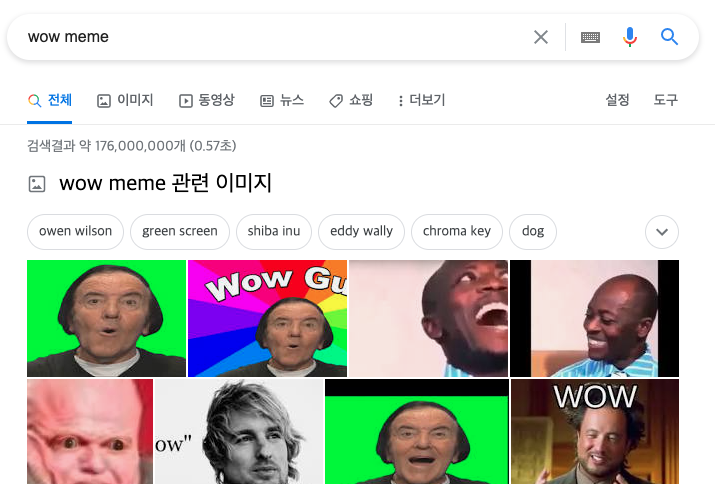
예를 들면 위와 같이 구글에 이미지 검색을 하였을 시 한번 업로드된 이미지는 검색을 새로 고침 하더라도 동일한 이미지가 나오게 된다.
그럼 이 이미지들을 매번 요청 할 때마다 같은 쿼리와 파일 로드를 반복 하게 되어 백엔드에 부하가 발생 되어진다.
이 부분을 해결하기 위해 이미지 캐싱 방식을 사용하였다.
Client <-> Nginx <--Proxy--> Backend APP
형태로 작동되어지는 서버였기 때문에 Nginx 의 캐싱 설정만 해주면 같은 주소로 호출 되었을 시 Nginx 자체에 캐쉬되어진 파일을 Backend APP 에 요청이 넘어가기 전에 반환을 하게되어 서버의 부담을 줄일 수 있게 되었다.
캐시 설정은 다음과 같았는데
proxy_cache_path /var/cache/nginx-tmp levels=1:2 keys_zone=my_zone:512m max_size=30000m inactive=1M;
proxy_cache_key "$scheme$request_method$host$request_uri";
캐시 키 값은 같은 메소드의 주소로 들어오는 것들이며 최대 30GB의 캐시가 가능하고 1달을 만료 일자로 지정하였다.
location ~* \.(?:ico|gif|jpe?g|png)$ {
proxy_cache_key "$scheme$request_method$host$uri$is_args$args";
proxy_cache my_zone;
# proxy_cache_methods GET;
access_log off;
add_header X-Proxy-Cache $upstream_cache_status;
expires 1M;
add_header Cache-Control public;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass <BACKEND_APP_URL>;
proxy_cache_valid 200 1M;
}
캐쉬되어질 타입은 .mp4, .gif, .ico, .jpeg, .jpg, .png 과 같은 미디어 정적 파일을 캐쉬 대상으로 지정하였다.
그리하여 얻어지는 성능은 놀라운데

741ms -> 4ms 로 로드 시간이 단축되는 것을 확인 할 수 있다.
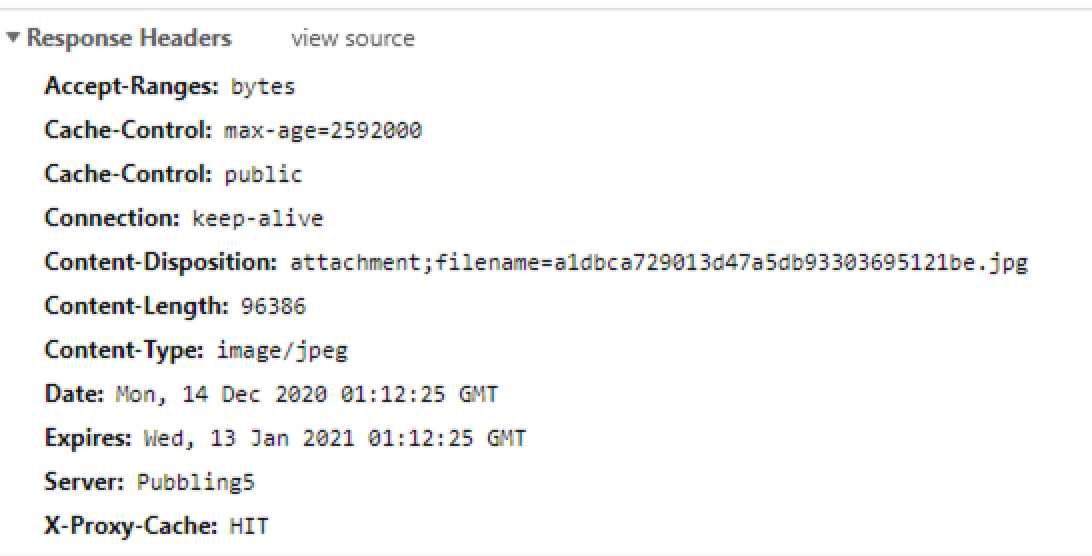
캐쉬되어짐 여부 확인은 Response 탭에서 확인이 가능한데
Expires 에서 해당 캐쉬된 데이터가 언제 만료되어질 것인지, X-Proxy-Cache 로 캐쉬 됨 (HIT) 캐쉬 되어지지 않음 (MISS) 로 확인 가능하다.